
Editorial
Training Automated Anomaly Detection Routines in Mobile Networks
The Virtual NOC (vNOC) solution uses AI to monitor network KPIs, leveraging historical data and statistical change point detection to issue alerts when performance starts to deteriorate.

For network operators, one key objective to maintain and increase profits is reducing customer churn by keeping customers satisfied. The best way to do this is to provide them with the best possible experience, which requires operators to be able to respond rapidly to any issues that arise in the network, ideally resolving them before they degrade the customer’s experience.
But today’s mobile networks are becoming ever-more complex and need to support continuously rising numbers of devices and applications, and 5G and the IoT are only exacerbating this trend. This also increases the load on networks, making it more difficult to monitor performance, and increasing the risk of dissatisfied customers.
Operators have network operation centers (NOCs) that receive alarms directly from network equipment when something is not working as it should be, which is useful for dealing with hardware and software faults. But the dynamic nature of today’s mobile networks means that there can be many reasons for degraded performance that are not directly related to equipment faults, instead being due to issues with subscriber device, how an application has been programmed, or other misconfiguration. As these kinds of issues do not typically trigger equipment alarms, standard NOCs may not be able to identify them before they affect performance and irritate customers.
One way to recognize issues in the network before they become a problem is to continuously monitor a set of defined KPIs, such as success rate and throughput. But this kind of monitoring can result in a need to follow dozens, or even hundreds, of KPIs in every cell in the network. As a mobile network can easily total hundreds of thousands of cells, this is impossible in a practical sense. Some changes are too small to detect even by a trained human eye.
Modern systems that incorporate AI and ML give us a better option, though. Elisa Polystar’s Virtual NOC (vNOC) solution features an AI-powered anomaly detection algorithm that continuously monitors KPIs throughout the network. Rather than simply waiting for these KPIs to cross a specified threshold, the vNOC ML Engine is trained with historical data and utilizes statistical change point detection to issue “performance alarms” at the point where performance begins to change for the worse.
As these alarms are issued almost immediately, this gives operators vital early warning of issues that will lead to dissatisfied customers, allowing them to be proactively resolved before customers notice a problem. For more details about how this system works, read the previous article here.
Taking Things Further by Training the System
No system is perfect, and there is room for improvement here as well. The current methodology uses what is known as “unsupervised” anomaly detection, where the ML Engine decides for itself what changes in KPIs should be flagged as anomalous. As not all performance alarms will directly relate to issues that degrade performance for customers, this means that a significant percentage of the performance alarms do not necessarily indicate an issue that needs to be resolved.
In fact, real-world results with an untrained and unsupervised anomaly detection algorithm indicate that around 30% of the performance alarms are “interesting”, i.e., they indicate an issue that needs to be reviewed and potentially resolved to make sure it does not degrade performance for customers. Even this relatively low figure represents a huge boon for operators, as the alarms are issued almost in real time, allowing them to rapidly investigate the alarms and resolve the ones that relate to real issues.
But it would be even better if the performance alarms were more precise. Elisa Polystar is currently engaged in an ongoing project with one mobile operator customer, working on a method to improve the precision of the performance alarms generated by the vNOC – with very promising results.
Human-Machine Collaboration
The new method is a good example of how modern AI/ML techniques help to promote cooperation between the technological system and the human experts who operate it – known as human–machine collaboration. This is where the true benefits of a well-designed machine learning tool can be seen, in a collaborative intelligence where the human experts train the AI, making it better at its job and freeing up the experts’ time. Rather than engaging in routine monitoring, the human experts can expend their effort where it truly brings value – for customers and companies.
The system that Elisa Polystar is developing adds an extra feedback layer into the routine: A human expert trains the system by examining batches of performance alarms that have been raised by the system. The expert categorizes and labels the alarms, informing the ML Engine about whether the alarm really represents an anomaly in the network that needs to be resolved. This information allows the ML algorithm to identify genuine anomalies more precisely in the future.
The system uses a specially designed, lightweight user interface that allows the human expert to very rapidly examine performance alarms raised by the system and give feedback to the system by applying labels to them. This allows the system to filter out many of the irrelevant performance alarms, improving the precision of the alarms and the efficiency of operators’ responses to them.
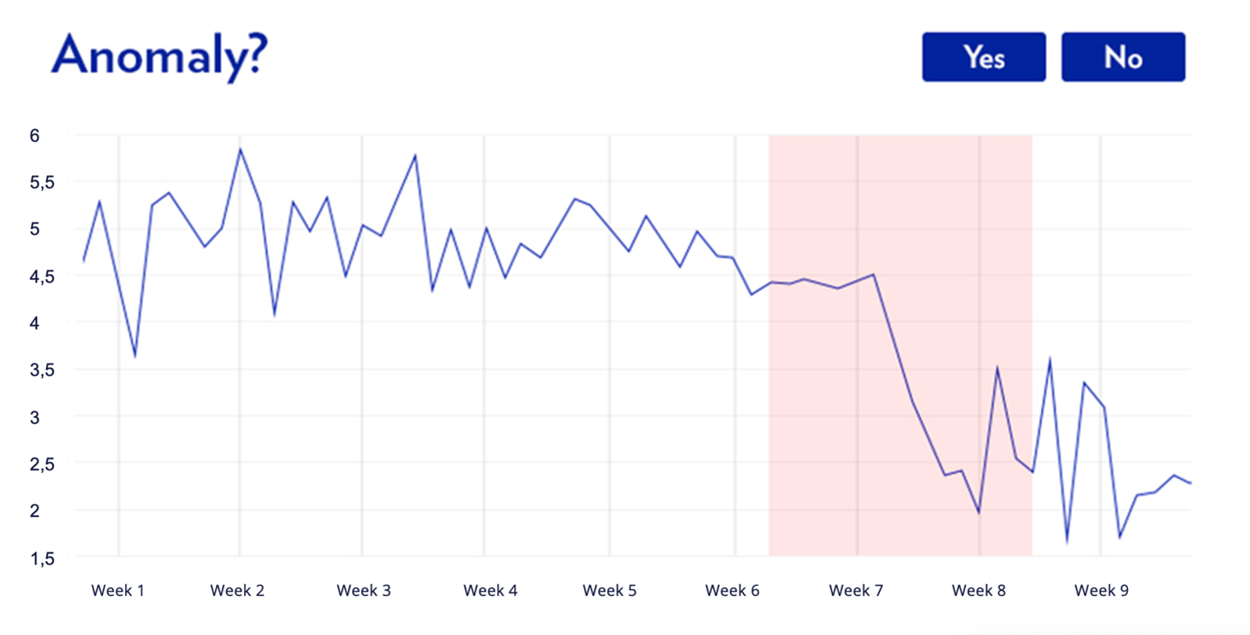
Early results from the system show extremely promising results. Following categorization and labelling of the performance alarms by a human expert, the precision of the system in producing actionable results from performance alarms increases from 30% to 70%. The experts at Elisa Polystar are confident that, with further development, this figure can be increased to as much as 80–90%.
As a further benefit, utilizing this expert feedback layer is not very labor-intensive and requires minimal effort from the human experts. Only a small sample of data for a specific KPI needs to be labelled to gain the benefit of improved precision in results. Most of the time, this means that the labelling effort needed from the human expert is measured in hours rather than days.
Development ongoing
Batch processing – labelling KPIs in a batch of anomalous results generated by the ML Engine – is the method currently being used, but it’s not the only potential method. It would be possible to operate this system as a continuous training layer, with the human experts categorizing and labelling performance alarms as part of their workflow in real time as they are flagged up by the system. However, there are potential drawbacks to doing it this way, such as inconsistency in labelling if different experts apply different criteria to labelling the alarms. Now, until these challenges are addressed, running the system in batch mode offers more consistent outcomes.
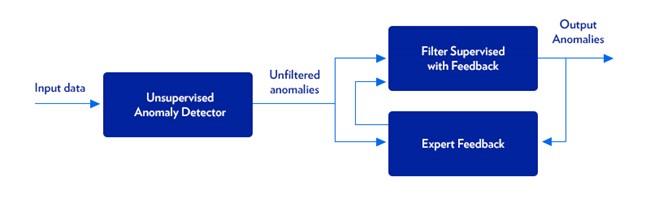
Of course, while it offers a significant step up in performance, this improved system is not perfect either. For some KPIs, improved labelling may not always improve the quality of the anomalies flagged by the system. In these cases, it may be necessary to implement changes in the way that the unsupervised model works.
Following the training, the system may also filter out a small number of “interesting” anomalies (those that require a response from the operator) as well. However, the impressive improvement in the precision of the alarms more than makes up for this, and the overall gains for operators are significant.
The next steps in the work are to further improve and streamline the user interface for labeling the anomalies, and to conduct further testing of different labeling methods: batch processing, continuous processing, or a hybrid method combining the two.
While the feedback system is not yet complete, it offers enormous potential for mobile operators, allowing them to focus their efforts where they will have the largest and most immediate impact. When operators can respond to performance-related issues in their network before they start to degrade the experience of customers, those customers are happier and more satisfied, reducing customer churn. In combination with improved focus and more efficiency in network monitoring, this system could also provide a clear boost to the bottom line for operators, too.